Authors vs. Readers: A Comparative Study of Document Metadata and Content in the WWW
My paper Authors vs. Readers: A Comparative Study of Document Metadata and Content in the WWW has been accepted for publication at this year’s ACM Symposium on Document Engineering, which will be held at the University of Manitoba, Winnipeg, Canada from August 28 - 31, 2007.
Quick Links
Abstract
Collaborative tagging describes the process by which many users add metadata in the form of unstructured keywords to shared content. The recent practical success of web services with such a tagging component like Flickr or del.icio.us has provided a plethora of user-supplied metadata about web content for everyone to leverage.
In this paper, we conduct a quantitative and qualitative analysis of metadata and information provided by the authors and publishers of web documents compared with metadata supplied by end users for the same content. Our study is based on a random sample of 100,000 web documents from the Open Directory, for which we examined the original documents from the World Wide Web in addition to data retrieved from the social bookmarking service del.icio.us, the content rating system ICRA, and the search engine Google. The data set of our experiments, called DMOZ100k06, is freely available for other research. We hope that the results of our study give researchers valuable insights for building and improving systems for document engineering, retrieval, and classification in the World Wide Web today.
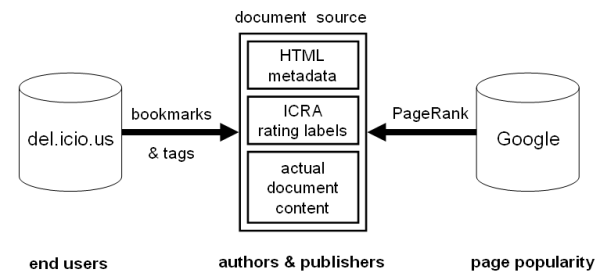
Note: I used my custom Delicious Python API for retrieving the relevant data from del.icio.us.
Paper
- Authors vs. Readers: A Comparative Study of Document Metadata and Content in the WWW (PDF)
Proceedings of 7th Intl’l ACM Symposium on Document Engineering (ACM DocEng), Winnipeg, Canada, August 2007, pp. 177-186, ISBN 978-1-59593-776-6 (ACM Link, BibTeX)
Presentation

The slides of my talk at the DocEng 2007 conference are available for download.
Acknowledgements
I would like to thank Alexandre Dulaunoy for his help with mirroring the HTML documents in the data set, and his comments while I was preparing the paper. Again, it’s been greatly appreciated, Alex!
Related Links
- List of my publications
- DMOZ100k06, a large research data set about document metadata based on a random sample of 100,000 web documents
- Delicious Python API, used for retrieving data from delicious.com