Performing an HDFS Upgrade of an Hadoop Cluster
In this guide I will describe how to upgrade the Distributed Filesystem (HDFS) of an Hadoop cluster. An HDFS upgrade might be required when you update the Hadoop software itself.
Before We Start
This guide should cover the majority of tasks and aspects of upgrading HDFS but it may not necessarily be complete. Feel free to provide your feedback and suggestions.
Apart from my own input, this article uses information from the Hadoop Upgrade guide, the HDFS User Guide and Tom White’s book Hadoop: The Definitive Guide (see References section at the bottom).
Background information on HDFS upgrades
An HDFS upgrade may be required when you upgrade from an older version of Hadoop to a newer version. For instance, an HDFS upgrade is required when you upgrade from Hadoop 0.20.2 to Hadoop 0.20.203.0.
An upgrade of HDFS makes a copy of the previous version’s metadata and data. Doing an upgrade does not double the storage requirements of the cluster, as the datanodes use hard links to keep two references (for the current and previous version) to the same block of data. This design makes it straightforward to roll back to the previous version of the filesystem, should you need to. You should understand that any changes made to the data on the upgraded system will be lost after the rollback completes.
You can keep only the previous version of the filesystem: you can’t roll back several versions. Therefore, to carry out another upgrade to HDFS data and metadata, you will need to delete the previous version, a process called finalizing the upgrade. Once an upgrade is finalized, there is no procedure for rolling back to a previous version.
How to check whether an HDFS upgrade is required
Unfortunately, the most reliable way of finding out whether you need to upgrade the HDFS filesystem is by performing a trial on a test cluster (doh!).
If you have installed a new version of Hadoop and it expects a different HDFS layout version, the NameNode will refuse to run. A message like the following will appear in the NameNode logs:
File system image contains an old layout version -18.
An upgrade to version -31 is required.
Please restart NameNode with -upgrade option.
HDFS upgrade instructions
There are several steps you have to perform for upgrading HDFS. First, you have to perform some preparation steps before installing the new (updated) Hadoop software. Then, after having updated Hadoop (e.g. from version 0.20.2 to 0.20.203.0), you will follow-up with another set of steps to actually start the HDFS upgrade and, after successful testing, finalize it.
Before you install the new Hadoop version
-
Make sure that any previous upgrade is finalized before proceeding with another upgrade. To find out whether the cluster needs to be finalized run the command:
$ hadoop dfsadmin -upgradeProgress status - Stop all client applications running on the MapReduce cluster.
-
Stop the MapReduce cluster with
$ stop-mapred.shand kill any orphaned task process on the TaskTrackers.
- Stop all client applications running on the HDFS cluster.
- Perform some sanity checks on HDFS.
-
Perform a filesystem check:
$ hadoop fsck / -files -blocks -locations > dfs-v-old-fsck-1.log - Fix HDFS to the point there are no errors. The resulting file will contain a complete block map of the file
system.
Note: Redirecting the
fsckoutput is recommend for large clusters in order to avoid time consuming output toSTDOUT. -
Save a complete listing of the HDFS namespace to a local file:
$ hadoop dfs -lsr / > dfs-v-old-lsr-1.log -
Create a list of DataNodes participating in the cluster:
$ hadoop dfsadmin -report > dfs-v-old-report-1.log
-
- Optionally, copy all or unrecoverable only data stored in HDFS to a local file system or a backup instance of HDFS.
-
Optionally, stop and restart HDFS cluster, in order to create an up-to-date namespace checkpoint of the old version:
$ stop-dfs.sh $ start-dfs.sh - Optionally, repeat 5, 6, 7 and compare the results with the previous run to ensure the state of the file system remained unchanged.
- Create a backup copy of the
dfs.name.dirdirectory on the NameNode (if you followed my Hadoop tutorials:/app/hadoop/tmp/dfs/name). Among other important files, thedfs.name.dirdirectory includes the checkpoint fileseditsandfsimage. -
Stop the HDFS cluster.
$ stop-dfs.shVerify that HDFS has really stopped, and kill any orphaned DataNode processes on the DataNodes.
Install the new Hadoop version
Now you can install the new version of the Hadoop software.
Note: Make sure to update any symlinks you are using; e.g. if you have symlinks such as /usr/local/hadoop →
/usr/local/hadoop-0.20.203.0.
After you have installed the new Hadoop version
- Optionally, update the
conf/slavesfile before starting to reflect the current set of active nodes. - Optionally, change the configuration of the NameNode’s and the JobTracker’s port numbers (i.e. the
fs.default.nameproperty inconf/core-site.xmlplusconf/hdfs-site.xmland themapred.job.trackerproperty inconf/mapred-site.xmlrespectively) in order to ignore unreachable nodes that are still running the old version (with the old port numbers), preventing them from connecting and disrupting system operation. - Start the actual HDFS upgrade process.
-
Upgrade the NameNode by converting the checkpoint to the new version format
$ hadoop-daemon.sh start namenode -upgradeNote: You need to add the
-upgradeswitch only once for actual upgrade process. Once it has successfully completed, you can start the NameNode viahadoop-daemon.shstart-dfs.shandstart-all.shlike you’d normally do. The un-finalized upgrade will be in effect until you either finalize the upgrade to make it permanent or until you perform a rollback of the upgrade (see below).The NameNode log will show messages like the following:
# NameNode log file 2011-06-21 14:40:32,579 INFO org.apache.hadoop.hdfs.server.common.Storage: Upgrading image directory /path/to/nn_namespace_dir. old LV = -18; old CTime = 0. new LV = -31; new CTime = 1308660032579 2011-06-21 14:40:32,581 INFO org.apache.hadoop.hdfs.server.common.Storage: Image file of size 8447 saved in 0 seconds. 2011-06-21 14:40:32,639 INFO org.apache.hadoop.hdfs.server.common.Storage: Upgrade of /path/to/nn_namespace_dir is complete. 2011-06-21 14:40:32,639 INFO org.apache.hadoop.hdfs.server.common.Storage: Upgrading image directory /path/to/nn_namespace_dir_bk. old LV = -18; old CTime = 0. new LV = -31; new CTime = 1308660032579 2011-06-21 14:40:32,644 INFO org.apache.hadoop.hdfs.server.common.Storage: Image file of size 8447 saved in 0 seconds. 2011-06-21 14:40:32,650 INFO org.apache.hadoop.hdfs.server.common.Storage: Upgrade of /path/to/nn_namespace_dir_bk is complete. 2011-06-21 14:40:32,651 INFO org.apache.hadoop.hdfs.server.namenode.NameCache: initialized with 0 entries 0 lookups 2011-06-21 14:40:32,652 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Finished loading FSImage in 441 msecs 2011-06-21 14:40:32,660 INFO org.apache.hadoop.hdfs.StateChange: STATE* Safe mode ON. -
The NameNode upgrade process can take a while depending on how many files you have. You can follow the process by inspecting the NameNode logs, by running “
hadoop dfsadmin -upgradeProgress statusand/or by accessing the NameNode Web UI. Once the upgrade process has completed, the NameNode Web UI will show a message similar toUpgrade for version -31 has been completed. Upgrade is not finalizedYou will finalize the upgrade in a later step. Right now, the NameNode is in Safe Mode waiting for the DataNodes to connect.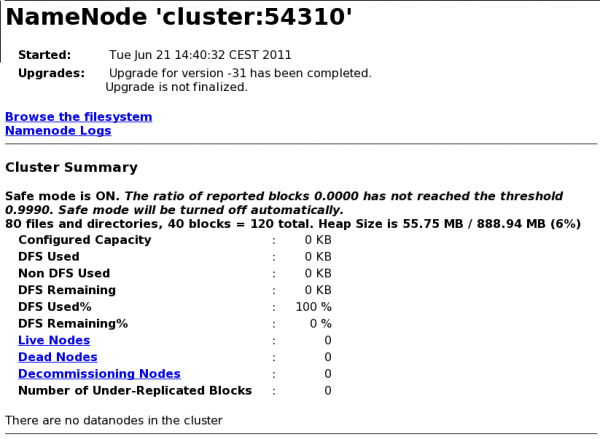
An example status output of the
upgradeProgresscommand at this stage:$ hadoop dfsadmin -upgradeProgress status Upgrade for version -31 has been completed. Upgrade is not finalized. -
Optionally, save a complete listing of the new HDFS namespace to a local file:
$ hadoop dfs -lsr / > dfs-v-new-lsr-0.logand compare it with
dfs-v-old-lsr-1.logyou created previously. -
Start the HDFS cluster. Since the NameNode is already running, only the DataNodes and the SecondaryNameNode will actually be started.
$ start-dfs.shNote: You do not need to add the
upgradeswitch here because it is only passed to the NameNode anyways, and the NameNode has already been instructed to perform an upgrade.After your DataNodes have completed the upgrade process, you should see a message
Safe mode will be turned off automatically in X seconds.in the NameNode Web UI. The NameNode should then automatically exit Safe Mode and HDFS will be in full operation. You can monitor the process via the NameNode Web UI and the NameNode/DataNode logs.# DataNode log file 2011-06-21 14:50:56,103 INFO org.apache.hadoop.hdfs.server.common.Storage: Upgrading storage directory /app/hadoop/tmp/dfs/data. old LV = -18; old CTime = 0. new LV = -31; new CTime = 1308660032579 2011-06-21 14:50:56,196 INFO org.apache.hadoop.hdfs.server.common.Storage: HardLinkStats: 1 Directories, including 0 Empty Directories, 0 single Link o perations, 1 multi-Link operations, linking 80 files, total 80 linkable files. Also physically copied 1 other files. 2011-06-21 14:50:56,196 INFO org.apache.hadoop.hdfs.server.common.Storage: Upgrade of /app/hadoop/tmp/dfs/data is complete.You can check the NameNode Web UI whether the NameNode has already exited Safe Mode (see screenshot below). Alternatively, you can run
hadoop dfsadmin -safemode get.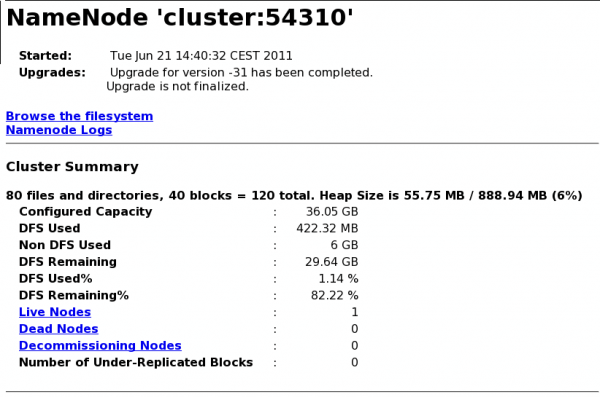
Note that the status output of the
upgradeProgresscommand should not have changed at this point:$ hadoop dfsadmin -upgradeProgress status Upgrade for version -31 has been completed. Upgrade is not finalized.
-
- Perform some sanity checks on the new HDFS
-
Create a list of DataNodes participating in the updated cluster.
$ hadoop dfsadmin -report > dfs-v-new-report-1.logand compare it with
dfs-v-old-report-1.logto ensure all DataNodes previously belonging to the cluster are up and running. -
Save a complete listing of the new HDFS namespace to a local file:
$ hadoop dfs -lsr / > dfs-v-new-lsr-1.logand compare it with
dfs-v-old-lsr-1.log. These files should be identical unless the format ofhadoop fs -lsrreporting or the data structures have changed in the new version. -
Perform a filesystem check:
$ hadoop fsck / -files -blocks -locations > dfs-v-new-fsck-1.logand compare with
dfs-v-old-fsck-1.log. These files should be identical, unless thehadoop fsckreporting format has changed in the new version.
-
-
Start the MapReduce cluster
$ start-mapred.sh - Let internal customers perform their own testing on the new HDFS filesystem version.
- Roll back or finalize the upgrade (optional).
Finishing the HDFS upgrade process
After you have initiated the HDFS upgrade in the sections above, you will eventually have to decide – hopefully after thorough testing – whether you want to stick to the upgraded HDFS (= your tests were successful) or to revert the HDFS upgrade (= your tests failed). The following two sections describe how to finalize (i.e. stick to) an HDFS upgrade and how to perform a rollback of an HDFS upgrade.
How to finalize an HDFS upgrade
If the HDFS upgrade worked out fine and your subsequent testing was successful, you may want to finalize the HDFS upgrade.
You can check with the following command whether the cluster needs to be finalized:
$ hadoop dfsadmin -upgradeProgress status
Run the actual finalize command to make the HDFS upgrade permanent:
$ hadoop dfsadmin -finalizeUpgrade
The -finalizeUpgrade command removes the previous version of the NameNode’s and DataNodes’ storage directories.
In the NameNode Web UI you should see a message "Upgrades: There are no upgrades in progress".
The NameNode logs should contain entries similar to the following:
# NameNode log file
2011-06-22 20:21:22,333 INFO org.apache.hadoop.hdfs.server.common.Storage: Finalizing upgrade for storage directory /app/hadoop/tmp/dfs/name.
cur LV = -31; cur CTime = 1308774082
2011-06-22 20:21:22,336 INFO org.apache.hadoop.hdfs.server.common.Storage: Finalize upgrade for /app/hadoop/tmp/dfs/name is complete.
Also, running hadoop dfsadmin will now report that there are no pending upgrades.
$ hadoop dfsadmin -upgradeProgress status
There are no upgrades in progress.
Note: The finalize upgrade procedure can run in the background without disrupting the performance of the Hadoop cluster.
It is worth mentioning that deleting files that existed before the upgrade does not free up real disk space on the DataNodes until the HDFS cluster is finalized.
The official HDFS User Guide in the Hadoop documentation provides the full instructions for HDFS Upgrade and Rollback.
How to roll back an HDFS upgrade
If the HDFS upgrade failed and/or your testing was not successful, you may want to revert the HDFS upgrade.
The official HDFS User Guide in the Hadoop documentation provides the full instructions for HDFS Upgrade and Rollback. This section only highlights the most important parts.
If there is a need to move back to the old version, you have to:
- Stop all client applications on the cluster.
- Stop the full cluster (MapReduce + HDFS).
- Distribute the previous version of Hadoop, i.e. the Hadoop version used before the attempted upgrade.
- Start the HDFS cluster with the rollback option. $ start-dfs.sh -rollback
The NameNode logs should contain entries similar to the following:
# NameNode log file
2011-06-22 19:31:54,039 INFO org.apache.hadoop.hdfs.server.common.Storage: Rolling back storage directory /app/hadoop/tmp/dfs/name.
new LV = -18; new CTime = 0
2011-06-22 19:31:54,041 INFO org.apache.hadoop.hdfs.server.common.Storage: Rollback of /app/hadoop/tmp/dfs/name is complete.
2011-06-22 19:31:54,042 INFO org.apache.hadoop.hdfs.server.common.Storage: Number of files = 1117
2011-06-22 19:31:54,191 INFO org.apache.hadoop.hdfs.server.common.Storage: Number of files under construction = 0
The DataNode logs should contain entries similar to the following:
# DataNode log file
2011-06-22 19:31:55,816 INFO org.apache.hadoop.hdfs.server.common.Storage: Rolling back storage directory /app/hadoop/tmp/dfs/data.
target LV = -18; target CTime = 0
2011-06-22 19:32:02,363 INFO org.apache.hadoop.hdfs.server.common.Storage: Rollback of /app/hadoop/tmp/dfs/data is complete.
The rollback will take some time to complete. The NameNode will stay in Safe Mode until all DataNodes have finished their rollback work and have registered back at the NameNode.
Also, running dfsadmin will now also report that there are no pending upgrades:
$ hadoop dfsadmin -upgradeProgress status
There are no upgrades in progress.
The HDFS is now reverted back to its previous state, i.e. the state before you run -upgrade.
References
- Hadoop Upgrade on the Hadoop Wiki
- HDFS User Guide for Hadoop 0.20.203.0
- File System Shell Guide for Hadoop 0.20.203.0
- Commands Guide for Hadoop 0.20.203.0
- Tom White, Hadoop: The Definitive Guide (2nd ed.), O’Reilly, pp. 316-319 (plus some other pages)