Wirbelsturm: 1-Click Deployments of Storm and Kafka clusters with Vagrant and Puppet
I am happy to announce the first public release of Wirbelsturm, a Vagrant and Puppet based tool to perform 1-click local and remote deployments, with a focus on big data related infrastructure. Wirbelsturm’s goal is to make tasks such as “I want to deploy a multi-node Storm cluster” simple, easy, and fun. In this post I will introduce you to Wirbelsturm, talk a bit about its history, and show you how to launch a multi-node Storm (or Kafka or …) cluster faster than you can brew an espresso.
- Wirbelsturm quick start
- Motivation
- Current Wirbelsturm features
- Is Wirbelsturm for me?
- Wirbelsturm in detail
- The long road of getting there
- Lessons learned: mistakes made along the way
- Summary
- Related work
Update May 27, 2014: If you want to build real-time data processing pipelines based on Kafka and Storm, you may be interested in kafka-storm-starter. It contains code examples that show to integrate Apache Kafka 0.8+ with Apache Storm 0.9+, while using Apache Avro as the data serialization format.
Wirbelsturm quick start
This section is an appetizer of what you can do with Wirbelsturm. Do not worry if something is not immediately obvious to you – the Wirbelsturm documentation describes everything in full detail.
Assuming you are using a reasonably powerful computer and have already installed Vagrant (1.4.x – 1.5.x is not supported yet) and VirtualBox you can launch a multi-node Apache Storm cluster on your local machine with the following commands.
$ git clone https://github.com/miguno/wirbelsturm.git
$ cd wirbelsturm
$ ./bootstrap # <<< May take a while depending on how fast your Internet connection is.
$ vagrant up # <<< ...and this step also depends on how powerful your computer is.
Done – you now have a fully functioning Storm cluster up and running on your computer! The deployment should have taken you significantly less time and effort than going through long blog posts or working through the official documentation. On top of that, you can now re-deploy your setup everywhere and every time you need it, thanks to automation.
Let’s take a look at which virtual machines back this cluster behind the scenes:
$ vagrant status
Current machine states:
zookeeper1 running (virtualbox)
nimbus1 running (virtualbox)
supervisor1 running (virtualbox)
supervisor2 running (virtualbox)
Storm also ships with a web UI that shows you the cluster’s state, e.g. how many nodes it has, whether any processing jobs (topologies) are being executed, etc. Wait 20-30 seconds after the deployment is done and then open the Storm UI at http://localhost:28080/.
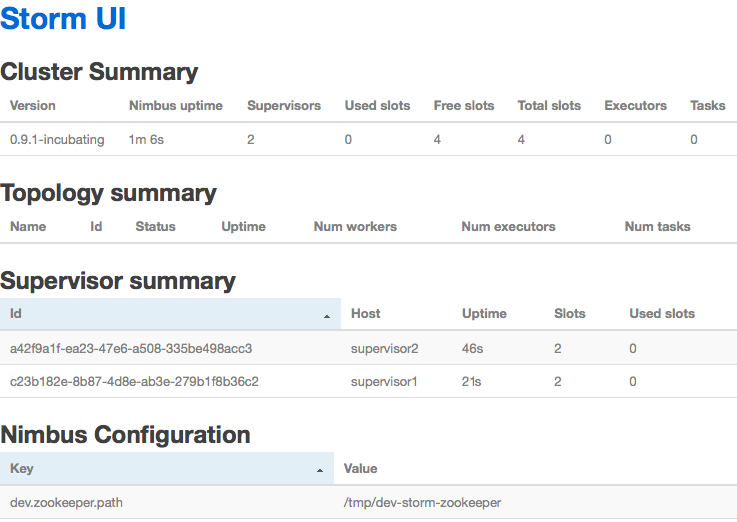
What’s more, Wirbelsturm also allows you to use Ansible to interact with the deployed machines via its ansible wrapper script:
$ ./ansible all -m ping
zookeeper1 | success >> {
"changed": false,
"ping": "pong"
}
supervisor1 | success >> {
"changed": false,
"ping": "pong"
}
nimbus1 | success >> {
"changed": false,
"ping": "pong"
}
supervisor2 | success >> {
"changed": false,
"ping": "pong"
}
Want to run more Storm slaves? As long as your computer has enough horsepower you only need to change a single number
in wirbelsturm.yaml:
# wirbelsturm.yaml
nodes:
...
storm_slave:
count: 2 # <<< changing 2 to 4 is all it takes
...
Then run vagrant up again and shortly after supervisor3 and supervisor4 will be up and running.
Want to run an Apache Kafka broker? Just uncomment the kafka_broker section in your
wirbelsturm.yaml that it looks similar to the following example snippet (only remove the leading # characters, do not remove any whitespace):
# wirbelsturm.yaml
nodes:
...
# Deploys Kafka brokers.
kafka_broker:
count: 1
hostname_prefix: kafka
ip_range_start: 10.0.0.20
node_role: kafka_broker
providers:
virtualbox:
memory: 1536
aws:
instance_type: t1.micro
ami: ami-86cdb3ef
security_groups:
- wirbelsturm
...
Then run vagrant up kafka1. Now you have Kafka running alongside Storm.
Once you have finished playing around, you can stop all the machines in the cluster again by executing
vagrant destroy.
Motivation
Let me use an analogy to explain the motivation to build Wirbelsturm. While I assume every last one of us wants to work somehow like this…

…most of our actual time is rather spent on doing something like that:

Without any automated deployment tools the task of setting up cluster environments with (say) Storm or Kafka is simply a very time-consuming, complicated, and – let’s face it – mind-numbingly boring experience. So the motivation for Wirbelsturm was really simple: first, minimize frustration, and second, help others.
While these were the primary reasons there were also secondary aspects: Wirbelsturm should integrate nicely with existing deployment infrastructures and the associated skills of Operations teams – that’s why it is so heavily based on Puppet, though e.g. Chef and Ansible would have been good candidates, too. Also, it should allow you to perform local deployments (say, your dev laptop) as well as remote deployments (larger-scale environments, production, etc.) – that’s why Vagrant was added to the picture. You should also be able to easily transition from a Wirbelsturm/Vagrant backed setup to a “real” production setup without having to re-architect your deployment, switch tools, etc.
As such Wirbelsturm is one of the tools that help to make the process of going from “Hey, I have this cool idea” to “It’s live in production!” as simple, easy, and fun as possible. A developer should be free to completely screw up “his” test environment; two developers in the same team should always have the same copy of an environment; the integration environment of that team should look and feel the same way, too; and for sure that should apply to the production environment as well.
I think at this point the motivation should be pretty clear, and in the section Is Wirbelsturm for me? I list further examples on what you can do with Wirbelsturm.
Current Wirbelsturm features
In its first public release Wirbelsturm supports the following high-level features:
- Launching machines: Wirbelsturm uses Vagrant to launch the machines that make up your infrastructure as VMs running locally in VirtualBox (default) or remotely in Amazon AWS/EC2 (OpenStack support is in the works).
- Provisioning machines: Machines are provisioned via Puppet.
- Wirbelsturm uses a master-less Puppet setup, i.e. provisioning is ultimately performed through
puppet apply. - Puppet modules are managed via librarian-puppet.
- Wirbelsturm uses a master-less Puppet setup, i.e. provisioning is ultimately performed through
- (Some) batteries included: We maintain a number of standard Puppet modules that work well with Wirbelsturm, some of which are included in the default configuration of Wirbelsturm. However you can use any Puppet module with Wirbelsturm, of course. See Supported Puppet modules for more information.
- Ansible support: The Ansible aficionados amongst us can use Ansible to interact with machines once deployed through Wirbelsturm and Puppet.
- Host operating system support: Wirbelsturm has been tested with Mac OS X 10.8+ and RHEL/CentOS 6 as host machines. Debian/Ubuntu should work, too.
- Guest operating system support: The target OS version for deployed machines is RHEL/CentOS 6 (64-bit). Amazon
Linux is supported, too.
- For local deployments (via VirtualBox) and AWS deployments Wirbelsturm uses a CentOS 6 box created by PuppetLabs.
- Switching to RHEL 6 only requires specifying a different Vagrant box
in bootstrap (for VirtualBox) or a different AMI image in
wirbelsturm.yaml(for Amazon AWS).
- When using tools other than Vagrant to launch machines: Wirbelsturm-compatible Puppet modules are standard Puppet modules, so of course they can be used standalone, too. This way you can deploy against bare metal machines even if you are not able to or do not want to run Wirbelsturm and/or Vagrant directly.
Is Wirbelsturm for me?
Here are some ideas for what you can do with Wirbelsturm:
- Evaluate new technologies such as Kafka and Storm in a temporary environment that you can set up and tear down at will. Without having to spend hours and stay late figuring out how to install those tools. Then tell your boss how hard you worked for it.
- Provide your teams with a consistent look and feel of infrastructure environments from initial prototyping to development & testing and all the way to production. Banish “But it does work fine on my machine!” remarks from your daily standups. Well, hopefully.
- Save money if (at least some of) these environments run locally instead of in an IAAS cloud or on bare-metal machines that you would need to purchase first. Make Finance happy for the first time.
- Create production-like environments for training classes. Use them to get new hires up to speed. Or unleash a Chaos Monkey and check how well your applications, DevOps tools, or technical staff can handle the mess. Bring coke and popcorn.
- Create sandbox environments to demo your product to customers. If Sales can run it, so can they.
- Develop and test-drive your or other people’s Puppet modules. But see also beaker and serverspec if your focus is on testing.
Wirbelsturm in detail
Actually I will not talk a whole lot about Wirbelsturm itself in this blog post anymore. If I managed to spark your interest feel free to head over to the Wirbelsturm project page and start reading – and fooling around – there. There is also a list of supported Puppet modules in case you’re wondering what kind of software you can deploy with Wirbelsturm (summary: you can use any Puppet module with Wirbelsturm, but some are easier to use than others).
Instead I want to spend a few minutes in the next sections talking about what tasks and problems had to be solved to put Wirbelsturm together, and also share some lessons learned along the way.
The long road of getting there
What needed to be done to create the first version of Wirbelsturm? Here’s a non-comprehensive list, I hope my memory serves me well.
- Packaging the relevant software where official packages (here: RPMs for RHEL 6 family) weren’t available.
- The packaging code is also open sourced at e.g. wirbelsturm-rpm-kafka and wirbelsturm-rpm-storm.
- Of course the packages also need to be digitally signed for security reasons.
- Kudos to Jordan Sissel for creating fpm!
- Making this build process deterministic, and publish that code as open source, too. That is, don’t use an internal
infrastructure for that because a) people may not be easily able to reproduce it, and b) people may not trust what
strangers put together behind closed doors.
Think: Reflections on Trusting Trust.
- The code to deploy a Wirbelsturm build server – which is used to build and sign the RPMs – is available as open source at puppet-wirbelsturm_build.
- Understanding how to manage and host a public yum respository on Amazon S3. Please note that the idea has never
been to become a third-party package maintainer or third-party package repository. Instead the idea was to
provide just enough so that Wirbelsturm beginners can follow a quick start and have something deployed in a matter
of minutes. And then let the users leverage the provided tools (see above) to run their own show.
- Hosting some pre-built RPMs on a public yum repo also meant to check whether the license of the respective software would allow that, and under which conditions. I am not a lawyer and made my best effort to comply with all the respective licenses. If you have some concerns in this regard please do let me know!
- Learning that RHEL/CentOS 6 ships with significantly outdated versions of many packages, notably supervisord (but e.g. also nginx). Supervisord version 2.x turned out to be a problem in practice because a properly functioning process supervisor is highly recommended for running Storm & Co. in production. Hence supervisord version 3.x needed to be packaged because that version is not yet available for the RHEL 6 OS family in any “official” repository (e.g. EPEL’s version is outdated, too).
- Speaking of outdated or at least different versions: Ruby on RHEL/CentOS 6 and Amazon Linux: 1.8.x. On Mac OS X 10.9: 1.9.x. And then we also have different versions of Puppet etc. While every version discrepancy is likely to complicate development and testing, Ruby and Puppet versions were particularly annoying to deal with as they are “bootstrap” packages that we need as the foundation of any Puppet-based deployments. I eventually created ruby-bootstrap, which addresses a part of those problems.
- Many Puppet modules needed to be made. Where possible I tried to use existing modules as-is but in practice that goal was hard to hit. Some modules didn’t really work, some used completely different coding styles, some did support Hiera while others didn’t, and so on. I ended up creating several modules from scratch – e.g. puppet-kafka, puppet-storm, and puppet-zookeeper – as well as forking others. In the latter case, I tried to contribute back changes to the upstream project where possible and feasible (e.g. I contributed a bug fix to puppet-lib-file_concat). But because my plan was also to come up with a consistent style and feature support across all Puppet modules – notably Hiera support – the code of many forks stayed in that particular fork. Also, some bug fixes or features that I contributed back upstream were never merged, but since Wirbelsturm wouldn’t function properly without those changes I didn’t have an alternative to maintaining my own fork.
- I ran into many bugs in many places.
Vagrant couldn’t consistently deploy to AWS, for instance. Vagrant plugins
broke amidst Vagrant version upgrades.
RHEL support suddenly stopped working in Vagrant, which I fixed
and contributed back. I learned that Puppet has, for instance, a very weird way of handling boolean values when
defined in Hiera. Or requires you to resort to a hacky
mkdir -pbased workaround using exec to create directories recursively. Most of those problems weren’t huge deals, but in combination they turned out to be death by a thousand cuts. - Separating Puppet code from Wirbelsturm code. I didn’t know about librarian-puppet during the first early versions of Wirbelsturm, which made it more difficult than necessary for Wirbelsturm users to keep their installations up to date. In the beginning they needed to change Puppet code in place, i.e. files checked into the Wirbelsturm git repo, so they would often run into merge conflicts when pulling the latest upstream changes. This unfortunate problem was resolved once I introduced librarian-puppet.
- Speeding up local deployments. If I recall correctly Mitchell Hashimoto – the creator of Vagrant – actually tried parallel VM creation at some point but his (host) machine was completely overwhelmed by this, and the feature was not introduced officially into Vagrant. However, what is still possible is to perform the provisioning of booted VMs in parallel. But…the Puppet provisioner of Vagrant does not support that. I therefore created a wrapper shell script based on para-vagrant.sh so that you can benefit from faster local deployments when using Wirbelsturm.
- Adding support for Ansible turned out to be quick and easy, once I understood how to create dynamic inventory scripts. 30 mins total.
- Automating the setup steps for Amazon AWS has been tricky. Apart from so-so Vagrant support for AWS, there were a couple of additonal problems I ran into. I remember issues with Amazon’s implementation of cloud-init when using custom AMI, for instance. Figuring out how to configure DNS in AWS (currently Wirbelsturm uses Amazon Route 53) took some time. Other tasks I remember include automatically creating restricted IAM users and tighter security groups. I am still not perfectly happy with the Wirbelsturm user experience when deploying to AWS, and for a number of reasons listed in the AWS related documentation of Wirbelsturm a code refactoring may be possible in the near future.
- After reading through the various issues listed above you may also understand now why at some point I decided to postpone supporting any other operating system than the RHEL 6 OS family (which includes CentOS and Amazon Linux). There were simply too many moving parts, and trying to tackle e.g. Debian/Ubuntu as well might have significantly delayed the progress on Wirbelsturm.
Lessons learned: mistakes made along the way
The wall of shame. But hey, hindsight is 20/20.
- Underestimating the amount of work it eventually took. See the previous section, and even what I wrote there is not the complete picture. Now, thanks to good roadmap planning early adopters of Wirbelsturm were productive from the very early beginning, and a close feedback loop helped a lot to keep the project on track and running in the right direction. Still the amount of work that actually needed to go into Wirbelsturm was significantly more than anticipated. It wasn’t as easy as going through Vagrant’s Puppet provisioner documentation and writing a few lines of Puppet code. In retrospect, knowing what I know today, Wirbelsturm could have been built much faster though.
- Not realizing quickly enough how valuable it is to separate code from configuration data in Puppet manifests, using Hiera. Particularly because this is so second-nature when coding in “real” programming languages instead of Puppet (which is a DSL on top of Ruby). To my defense I can only say that my hands-on knowledge of Puppet was very limited at the beginning, and I hadn’t even heard about Hiera (and a lot of people I talked to didn’t use it). In retrospect I should have spent more time up-front figuring out what the Puppet ecosystem had in store to address the code-vs-data problem, because it was pretty obvious right from the beginning that mixing the two would quickly lead to pain.
- Adding tests to Puppet modules too soon and too late. At the beginning the Puppet modules were refactored a lot in the quest of finding a reasonably good coding style, writing idiomatic Puppet manifests, etc. – and here dragging unit tests along the way turned out to be a chore and a waste of time. So I stopped writing tests. While that decision was ok, I made the mistake of postponing the re-introduction of proper tests for too long once the code across the modules became more stable. Well, at least puppet-kafka and puppet-storm have a good base test setup now thanks to puppet-module-skeleton, which means there isn’t any excuse left to postpone adding meaningful tests.
Of course there were more mistakes, but the ones above were the most noteworthy ones. :-)
Summary
I am really happy that Wirbelsturm is finally available as free and open source software. Hopefully it will help you to quickly get up and running with technologies such as Graphite, Kafka, Storm, Redis, and ZooKeeper. Enjoy!
Update May 27, 2014: If you want to build real-time data processing pipelines based on Kafka and Storm, you may be interested in kafka-storm-starter. It contains code examples that show to integrate Apache Kafka 0.8+ with Apache Storm 0.9+, while using Apache Avro as the data serialization format.
Related work
The following projects are similar to Wirbelsturm:
- storm-deploy – Deploys Storm clusters to AWS, by Nathan Marz, the creator of Storm. storm-deploy has been around for much longer than Wirbelsturm, so it might be more mature. It is a nice example of a deployment tool implemented in Clojure, using pallet and jclouds. Because of jclouds you should also be able to deploy to clouds other than AWS, though I haven’t found examples or documentation references on how to do so. (If you have pointers please let me know.) Unfortunately, its Clojure roots may make storm-deploy less popular within Operations teams, who typically are more familiar with tools such as Puppet, Chef, or Ansible. Also, storm-deploy seems to address only Storm deployments, and you require additional tools to deploy any other infrastructure pieces that you require (or enhance storm-deploy).
- kafka-deploy – Deploys Kafka to AWS, also by Nathan Marz. It has the same pros and cons as storm-deploy. Unfortunately, kafka-deploy has seen any updates since two years (Feb 2012), which is around the time it was originally published.
Commercial Hadoop vendors have also begun to integrate Storm into their product offerings:
- Apache Storm at HortonWorks – HortonWorks are working on Storm support for their product line. In this context they have added Storm support to their so-called Hortonworks Sandbox, which is a self-contained virtual machine with Hadoop & Co. pre-configured.
- If I recall correctly MapR were also looking at integrating Storm into their platform, but I could not find more concrete details apart from a few news articles and blog posts.
Another way of deploying Storm is via platforms such as Hadoop YARN and Apache Meos:
- storm-on-yarn – Enables Storm clusters to be deployed into machines managed by Hadoop YARN. The project says it is still a work in progress.
- storm-mesos – Storm integration with the Mesos cluster resource manager. The project says storm-mesos runs in production at Twitter.
Lastly, there are also a few open source Puppet modules for Hadoop, Kafka, Storm, ZooKeeper & Co. I don’t want to give an comprehensive overview of these modules in this post, but you can head over to places such as PuppetForge and GitHub and take a look yourself. Feel free to drop those modules into Wirbelsturm and give them a go!